هیچ محصولی در سبد خرید نیست.


تگ noindex چیست؟ جامعترین آموزش حرفهای سئو ۲۰۲۵
وقتی «ایندکسنشدن» بهترین استراتژی سئو استگاهی در سئو، بهترین حرکت «هیچ حرکتی» در نتایج جستجو است! عجیب شد؟ بگذارید روشنش کنیم: همیشه قرار نیست هر صفحهای از سایت شما در Google Index بنشیند و برای هر کوئری رقابت کند. بعضی صفحات، اگر در نتایج ظاهر شوند، هم برای کاربر مفید نیستند و هم برای برند شما ارزشآفرین نیستند؛ حتی میتوانند بودجه خزش (Crawl Budget) را بسوزانند و سیگنالهای کیفیت را مخدوش کنند. اینجاست که یک دستور ساده اما قدرتمند وارد بازی میشود: noindex.
noindex (نوایندکس) یعنی به رباتهای موتور جستجو بگوییم: «لطفاً این صفحه را ایندکس نکن.» نه کمتر، نه بیشتر. این تصمیم در ظاهر کوچک، در عمل میتواند نظم اطلاعات سایت شما را سر و سامان دهد، «نویزهای جستجویی» را کم کند، و تمرکز ایندکس را روی صفحات با قصد جستجوی واضح (Search Intent) نگه دارد. درست مثل مثلِ قدیمی «هر سخن جایی و هر نکته مکانی»، در سئو هم «هر صفحه جایی» دارد؛ جای بعضی صفحات داخل سایت است، نه در صفحه نتایج گوگل.
اما چرا باید سراغ noindex برویم؟ چون همه صفحات ارزش جستجویی ندارند: صفحات لاگین، تشکر از خرید (Thank-You)، نتایج جستجوی داخلی، گزارشهای آزمایشی A/B، آرشیوهای تاریخ/نویسندهی کممحتوا، یا نسخههای Stage/Pre-prod. اگر این صفحات وارد نتایج شوند، برای کاربر گیجکنندهاند و برای شما «فرصتسوز». با noindex tag میگوییم: «گوگل جان، اینها را ببین، بخوان (اگر لازم است)، اما داخل نتایجت نشان نده.»
نکتهی مهمتر اینکه noindex با «crawl» فرق دارد. Crawl یعنی بازدید و مطالعه صفحه توسط ربات؛ Index یعنی ثبت و نمایش در نتایج. شما ممکن است بخواهید صفحهای کرال شود (تا لینکها و سیگنالها عبور کنند) اما ایندکس نشود. این همان الگوی آشنای noindex, follow است. اگر لینکهای ارزشمند داخل صفحه دارید، با این ترکیب هنوز «لینکاکوئیتی» را به مقصد منتقل میکنید، بیآنکه خود صفحه در نتایج حاضر شود. سادگیاش فریبنده است، اما همین سادگی اگر جای درست استفاده نشود میتواند دردسرساز شود. پس قرار است قدمبهقدم دقیق برویم جلو.
در این مجموعهراهنما برای استارتاپ نمو، بهصورت کاربردی یاد میگیرید: noindex چی هست، چه فرقی با robots.txt و canonical دارد، چه زمانی از آن استفاده کنیم، چطور پیادهسازیاش کنیم (Meta Robots و X-Robots-Tag)، با چه دستورات دیگری همنشینی دارد (مثل indexifembedded، nosnippet)، و چطور با سرچ کنسول پایش کنیم. به زبان ساده و با مثالهای واقعی جلو میرویم تا در پایان، یک «تصمیمنامه حرفهای» در ذهنتان داشته باشید: هر وقت بین noindex، canonical و Disallow مرددید، در کمتر از یک دقیقه راه درست را انتخاب کنید.
یک تذکر دوستانه قبل از شروع: noindex چاقوی جراحی است، نه پتک! یعنی برای صفحات مشخص و با منطق روشن استفاده میشود، نه برای پنهان کردن مشکلات محتوایی یا دور زدن استراتژی. اگر صفحهای بالقوه ارزش جستجویی دارد اما ضعیف است، راه حل «تقویت محتوا»ست، نه noindex. با این دیدگاه، میرویم سر اصل مطلب. 
محتوا
پنهان
تگ noindex چیست؟
noindex یک «دستور ایندکسزدایی» (De-indexing Directive) برای رباتهای موتورهای جستجوست که به آنها میگوید: این URL در ایندکس قرار نگیرد. این دستور را معمولاً به یکی از دو روش اعمال میکنیم:
- Meta Robots Tag در HTML:
در بخش <head> صفحه قرار میگیرد و برای همان URL (و معمولاً نسخههای کَنُنیکالشده آن) اعمال میشود.
<meta name=”robots” content=”noindex, follow”>
- noindex = ایندکس نشود
- follow = لینکهای داخل صفحه دنبال شوند (سیگنالها عبور کنند)
- X-Robots-Tag در هدر HTTP (سمت سرور):
برای انواع فایلها که HTML نیستند (PDF، DOC، تصاویر) یا زمانی که نمیخواهید به HTML دست بزنید، از هدر پاسخ استفاده میکنید:
X-Robots-Tag: noindex, follow
این روش در Apache/Nginx با تنظیمات سروری (مثلاً در .htaccess یا کانفیگ Nginx) اعمال میشود و برای کنترل گروهیِ فایلها عالی است؛ نمونههای کُد را در بخشهای بعدی میآوریم.
تفاوت مفهومی «noindex» با «عدم خزش» و «کَنُنیکال»
برای درک عمیقتر، باید سه مفهوم را کنار هم ببینیم:
- Crawl (خزش): ربات صفحه را میبیند و محتوا/لینکها را میخواند.
- Index (ایندکس): موتور جستجو تصمیم میگیرد URL را در فهرست نتایج خود ذخیره و نمایش دهد.
- Ranking (رتبهبندی): اگر URL ایندکس شد، برای کوئریهای مرتبط رتبه میگیرد.
noindex فقط لایه Index را هدف میگیرد؛ یعنی ممکن است صفحه کرال شود، اما در ایندکس ذخیره نشود. همینجا دلیل محبوبیت ترکیب noindex, follow روشن میشود: شما از ایندکس دوری میکنید، ولی «جریان لینک» را حفظ میکنید.
در مقابل، Disallow در robots.txt یعنی «نرو ببین»؛ وقتی ربات اجازه خزش ندارد، معمولاً نمیتواند تشخیص دهد محتوا چه بوده و لینکها را هم نمیبیند (بهجز استثناهای خاص). پس اگر میخواهید صفحهای ایندکس نشود اما لینکهایش ارزش عبور داشته باشد، noindex بهتر از Disallow است. برعکس، اگر میخواهید اصلاً محتوا دیده نشود (مثلاً داکیومنت محرمانه روی سرور Stage)، معمولاً Disallow (بههمراه تدابیر امنیتی) مسیر درستتری است.
Canonical (rel=”canonical”) هم چیز دیگریست: میگوید «این URL نسخهی تکراری/جایگزین است؛ لطفاً نسخه مرجع فلان را ایندکس کن». canonical برای ادغام سیگنالها بین نسخههای هممحتوا عالی است؛ اما برای حذف از ایندکس ابزار اصلی نیست. اگر هدف «حذف نمایش» است، noindex صریحتر و مطمئنتر عمل میکند.
noindex با چه مقادیری میآید؟
- noindex, follow: رایجترین و توصیهشده برای صفحاتی که نمیخواهید دیده شوند، اما لینکهای داخلشان مهم است (مثلاً صفحات فیلتر نتایج، Search داخلی، یا صفحه Thank-You با لینکهای راهنما).
- noindex, nofollow: گاهی برای صفحات حساس یا آزمایشی که نمیخواهید حتی لینکسیگنال عبور کند. توجه کنید که برخی موتورهای جستجو ممکن است رفتار nofollow را بهصورت «hint» (نه الزام) در نظر بگیرند؛ پس روی آن برای «انسداد مطلق سیگنال» حساب بانکگونه باز نکنید.
- noindex تنها: اگر مقدار follow را نگذارید، بسیاری از رباتها «follow» را بهصورت پیشفرض در نظر میگیرند (اما شفافنویسی همیشه بهتر است).
نکتهی ظریف: اثر noindex آنی نیست. ربات باید صفحه را ببیند (Crawl) تا دستور را دریافت کند؛ پس اگر ساعتی بعد در نتایج تغییری ندیدید، طبیعی است. فرکانس خزش، اعتبار دامنه، و پیوندهای داخلی/خارجی روی سرعت اعمال اثر مؤثرند. در بخش «پایش در سرچ کنسول» یاد میگیرید چطور این روند را رصد کنید.
چه زمانی از تگ noindex استفاده کنیم؟
برای تصمیمگیری، یک معیار ساده داشته باشید: «آیا این URL پاسخدهندهی یک قصد جستجوی واقعی و مستقل است؟» اگر نه، نامزد خوبی برای نو ایندکس است. نمونههای کلاسیک:
- صفحات سیستمی/کاربردی: Login، Cart، Checkout (در برخی سناریوها)، Thank-You، Profile Settings.
- نتایج جستجوی داخلی و Faceted Navigation که موجب تولید بینهایت ترکیب پارامتر میشوند.
- آرشیوهای کمارزش جستجویی مثل برچسب/نویسنده/تاریخ، وقتی محتوای یونیک و هدفمند ندارند.
- نسخههای Stage/Pre-prod یا صفحات آزمایشی A/B (در کنار راهکارهای امنیتی).
- محتواهای موقت که کاربرد جستجویی ندارند اما برای سفر کاربر درون سایت ضروریاند.
و برعکس، اگر صفحهای پتانسیل رتبهگیری و جذب ترافیک دارد اما فعلاً ضعیف است، no index راهحل کوتاهمدتِ اضطراری است، نه راهحل دائمی. برای این موارد، برنامهی ارتقای محتوا (On-page، E-E-A-T، چندرسانهای، لینکسازی داخلی) را جدی بگیرید.
noindex چه چیزی را «مسدود» نمیکند؟
این سوءبرداشت رایج است که noindex یعنی «نامرئی شدن همهچیز». نه؛ noindex نمایش در نتایج را متوقف میکند، ولی ذاتاً جلوی خزش را نمیگیرد. اگر قصد دارید رباتها اصلاً صفحه را نبینند، جای شما در robots.txt (Disallow) یا راهکارهای امنیتی (Authentication، IP Whitelist، Password) است. همچنین اگر URL از بیرون زیاد لینک گرفته باشد، ممکن است آدرسِ URL (بیمتن) در نتایج ظاهر شود؛ برای مدیریت این سناریوها باید ترکیب سیاستها را درست بچینید (در بخشهای بعدی با ماتریس تصمیم سراغش میرویم).
یک نگاه فنی کوتاه: چرا «follow» کنار noindex منطقی است؟
از دید معماری اطلاعات، بسیاری از صفحات «کمارزش جستجویی» در عین حال پلهای مهم ناوبری (Navigation) هستند. مثلاً صفحه تشکر که لینک «محتوای پیشنهادی» دارد، یا نتایج جستجوی داخلی که به صفحات محصول میپیوندند. اگر nofollow کنید، ممکن است بخشی از سیگنالهای مسیریابی لینک را بیجهت قطع کنید. بنابراین، الگوی پیشفرضِ پیشنهادی برای اغلب سناریوها noindex, follow است؛ مگر اینکه دلیل امنیتی/آزمایشی خاصی داشته باشید.
خطاهای رایج در استفاده از noindex (یک ذره جلوتر از زمان خودش!)
برای اینکه از همین ابتدا از دردسر دور بمانید:
- همزمان کردن Disallow با noindex روی یک URL: اگر کرالر اصلاً وارد صفحه نشود، دستور noindex را نمیبیند و ممکن است ایندکس شدن «ناقص» یا نمایش URL-only رخ دهد.
- جمع کردن canonical به یک URL دیگر همراه با noindex: سیگنال متناقض است؛ یکی میگوید «این را ایندکس نکن»، دیگری میگوید «ایندکس را بده به فلانی». معمولاً یکی را انتخاب کنید: اگر هدف حذف است، noindex؛ اگر هدف ادغام نسخههاست، canonical.
- فراموش کردن هدرهای کش/CDN: اگر صفحهای را noindex کردید ولی نسخه کششدهی قدیمی تحویل داده میشود، ممکن است چند روز سردرگمی ایجاد کند. کش را مدیریت کنید.
- بیتوجهی به indexifembedded: اگر محتوایی دارید که فقط در حالت Embed باید ایندکس شود، تعامل آن با نو ایندکس را بشناسید.در بخش ترفندهای پیشرفته بهتفصیل میآید.
نمونههای مینیمال (برای تکمیل تعریف؛ جزییات کاملتر در بخش پیادهسازی)
HTML (Meta Robots):
<head>
<meta name=”robots” content=”noindex, follow”>
<!– یا برای گوگل بهطور خاص: –>
<meta name=”googlebot” content=”noindex, follow”>
</head>
Apache (.htaccess — X-Robots-Tag برای PDF):
<FilesMatch “\.(pdf)$”>
Header set X-Robots-Tag “noindex, follow”
</FilesMatch>
Nginx (location برای تصاویر یک پوشه):
location ~* /internal-media/ {
add_header X-Robots-Tag “noindex, nofollow”;
}
این کدها را فعلاً بهعنوان «تصویر روشن از مفهوم» داشته باشید؛ در بخش «روشهای پیادهسازی» بهصورت سیستماتیک و با سناریوهای بیشتر سراغشان خواهیم رفت.
بیشتر بدانید درباره : پروپوزال سئو
چرا همین امروز به noindex فکر کنیم؟
- تمرکز ایندکس: اجازه دهید ایندکس گوگل صرفاً با URLهای هدفمند شما پر شود.
- کاهش نویز تحلیلی: گزارشهای سرچ کنسول واضحتر میشود؛ بهجای صفحات کمارزش، روی صفحات درآمدزا تمرکز میکنید.
- بهبود تجربه کاربر از SERP: کاربر بهجای برخورد با صفحات سیستمی، با مقصدهای محتوایی درست مواجه میشود.
- مدیریت بهتر لینکاکوئیتی: با noindex, follow، جریان لینک حفظ میشود اما «دعوتنامه حضور در نتایج» صادر نمیکنید.
به طور سادهتر بگوییم: noindex یک فیلتر حرفهای برای نظم دادن به ایندکس شماست. حالا که تعریف و منطقش روشن شد، در بخش بعدی (گام دوم) وارد تفاوت noindex با robots.txt و canonical میشویم و یک چارچوب تصمیمگیری محکم میسازیم تا هیچوقت بین این سه راهی نمانید.
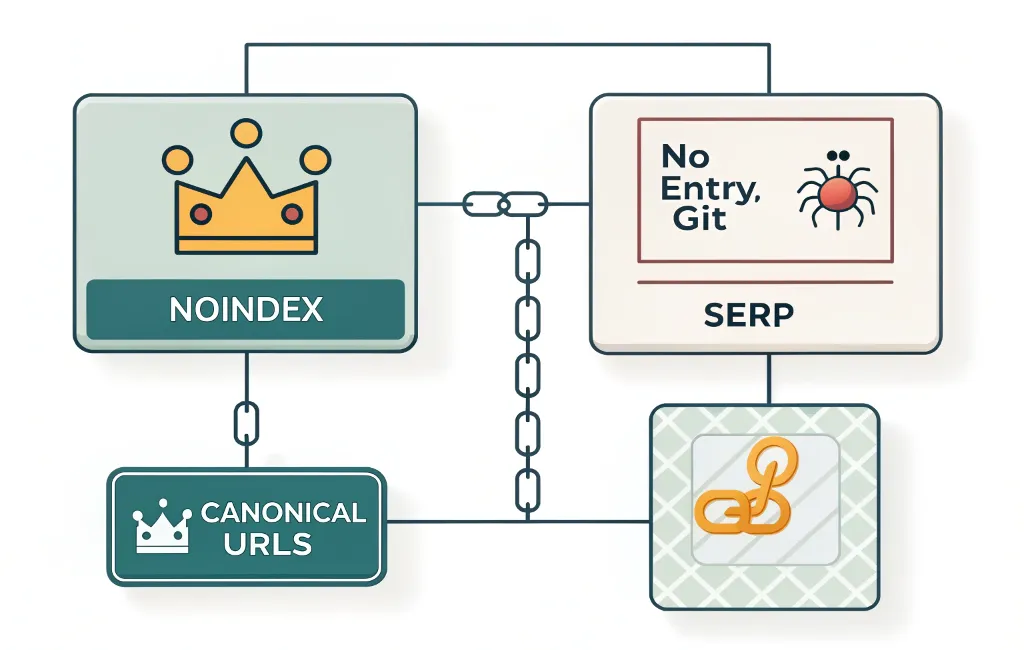
تفاوت تگ noindex با robots.txt و canonical
یکی از اشتباهات همیشگی سئوکارها و وبمسترها اینه که وقتی میخوان صفحهای در نتایج گوگل دیده نشه، مستقیم سراغ فایل robots.txt میرن و عبارت Disallow رو براش مینویسن. اما حقیقت اینه که robots.txt فقط جلوی خزش (Crawl) رو میگیره، نه ایندکس (Index) رو.
اجازه بده با یک مثال ملموستر موضوع رو باز کنیم.فرض کن سایتت یه صفحهی خصوصی داره به نام /checkout/. حالا تو داخل فایل robots.txt نوشتی:
User-agent: *
Disallow: /checkout/
گوگل این دستور رو میفهمه و وارد صفحه نمیشه. اما چون ممکنه از جای دیگهای به این URL لینک داده باشی (مثلاً از فوتر سایت یا از دامنههای دیگه)، گاهی URL صفحه بدون محتوا و فقط به شکل آدرس خام توی نتایج ظاهر میشه .اونوقت کاربر میگه: «این چیه دیگه؟ /checkout؟!» در واقع، گوگل صفحه رو ایندکس نکرده، اما چون نمیتونه محتواش رو بخونه، فقط URL رو نشون میده. نتیجه؟ نه خوشگل، نه کاربردی، نه حرفهای.
noindex:
دستور مؤدبانه به گوگل برای حذف از ایندکس در مقابل، وقتی از تگ نو ایندکس استفاده میکنی، به ربات میگی:«برو صفحه رو ببین، بخون، ولی داخل ایندکست ذخیره نکن.»
مثلاً:<meta name=”robots” content=”noindex, follow”>
در این حالت، گوگل با رضایت خاطر صفحه رو بررسی میکنه، لینکها رو دنبال میکنه، اما خودش رو موظف میدونه که اون صفحه توی نتایج نباشه. به این ترتیب، هم لینکسیگنال (Link Equity) از بین نمیره، هم صفحهای که نباید، توی نتایج ظاهر نمیشه.
به زبان سادهتر:
- robots.txt → «نرو اصلاً ببین.»
- noindex → «برو ببین، ولی نشون نده.»
و این فرق بزرگیه که باید همیشه یادت بمونه.
canonical:
وقتی دو صفحه شبیهان اما یکی باید پادشاه باشه!حالا برسیم به Canonical Tag (کَنُنیکال).گاهی شما چند صفحه با محتوای بسیار مشابه داری. مثلاً:
- /product/shirt-blue
- /product/shirt-blue?utm_source=ad
- /product/shirt-blue?sort=price
از دید گوگل، هر کدوم از این URLها نسخهای از یک محتوا هستن. اگر بذاری هر سه ایندکس بشن، ممکنه سیگنالها بینشون پخش بشه یا گوگل اشتباهی یکی رو انتخاب کنه.اینجا با Canonical به گوگل میگی:«همهی اینا یه خانوادهان؛ ولی نسخهی اصلی اینه»
<link rel=”canonical” href=”https://example.com/product/shirt-blue” />برخلاف نو ایندکس، تگ canonical نمیگه صفحه حذف شه، فقط میگه اولویت نمایش و رتبه با URL مرجع باشه.

تفاوت سهگانه بهصورت خلاصه
| ویژگی / ابزار | noindex | robots.txt | canonical |
| هدف اصلی | جلوگیری از ایندکس شدن | جلوگیری از خزش | ادغام نسخههای مشابه |
| اجازه خزش؟ | بله | خیر | بله |
| حذف از نتایج جستجو؟ | بله | ممکن است فقط URL خام بماند | خیر (فقط اولویت را تعیین میکند) |
| عبور لینکها (Follow) | در صورت تعیین follow، بله | خیر | بله |
| کاربردهای معمول | صفحات کمارزش یا موقت، Search داخلی، Login | فایلها یا دایرکتوریهای محرمانه | صفحات با محتوای تکراری یا پارامتر URL |
| نکته مهم | باید قابل Crawl باشد تا دیده شود | نباید برای پنهانسازی مشکلات محتوایی استفاده شود | نباید با noindex همزمان اعمال شود |
چطور تصمیم بگیریم؟ (راهنمای ذهنی سریع)یک راه ساده برای تصمیمگیری بین این سه ابزار، طرح سه سؤال کلیدی است:
- آیا میخواهم ربات صفحه را ببیند؟
- اگر نه → از robots.txt استفاده کن.
- آیا میخواهم صفحه در نتایج نمایش داده نشود، اما ربات آن را ببیند؟
- اگر بله → از noindex استفاده کن.
- آیا میخواهم سیگنالهای چند صفحهی مشابه را یکی کنم؟
- اگر بله → از canonical استفاده کن.
نکته طلایی: هر کدام از این ابزارها برای هدفی مشخص طراحی شدن؛ اگر اشتباه استفاده کنی، گوگل مثل شاگرد زرنگی که معلمش گیجش کرده، شروع میکنه به حدس زدن — و حدسهای گوگل معمولاً به نفع تو نیست! چند سناریوی واقعی برای درک بهتر:
سناریو ۱: صفحات تستی A/Bمیخواهی صفحه آزمایشی طراحی A رو با طراحی B مقایسه کنی. نتیجه برای گوگل بیارزش است، اما لینکهای داخلی مهماند.noindex, follow بهترین گزینه است.
سناریو ۲: فایلهای پشتیبان یا محرمانه (Backup, Admin)نمیخواهی گوگل حتی آنها را ببیند.در robots.txt Disallow بنویس یا دسترسی سرور را محدود کن.
سناریو ۳: پارامترهای تکراری (utm, sort, color)صفحات متفاوت از نظر URL اما محتوای یکسان دارند.canonical به نسخهی اصلی.
سناریو ۴: صفحه تشکر از خرید (Thank You Page)صفحهی سیستمی است، اما لینکهای مفید دارد.noindex, follow تا سیگنالها حفظ شوند.
سناریو ۵: صفحه عضویت / لاگین فقط کاربران عضو باید ببینندش.بسته به هدف: اگر عمومی نیست، Disallow؛ اگر عمومی است اما بیارزش جستجویی، no index.
اشتباه مرگبار: ترکیب نادرست noindex و Disallow
بعضیها فکر میکنن اگر بخوان صددرصد مطمئن شن صفحهای ایندکس نشه، بهتره هر دو رو با هم بذارن: هم no index، هم Disallow.اما این دقیقاً مثل اینه که در رو قفل کنی، بعد از پشت در داد بزنی: «هی گوگل! لطفاً نیا اینجا!» گوگل اصلاً وارد صفحه نمیشه که دستور تگ نو ایندکس رو ببینه! نتیجه؟ URL ممکنه در نتایج بمونه، حتی با عنوان «بدون توضیح» یا فقط آدرس.پس همیشه یادت باشه:
- اگر هدفت «ایندکسنشدن» است → فقط no index.
- اگر هدفت «کرالنشدن» است → فقط Disallow.
نکته پیشرفته: تعامل canonical و no index
وقتی روی صفحهای تگ نو ایندکس داری، canonical آن صفحه به نسخهی دیگر بیمعنی میشود. چرا؟ چون گوگل میگه:«تو خودت گفتی این صفحه نباشد، پس canonicalش را هم نادیده میگیرم.»اگر واقعاً میخواهی گوگل فقط نسخهی دیگر را ایندکس کند، از canonical بهتنهایی استفاده کن، نه ترکیبش با noindex.اما اگر هدفت حذف قطعی از نتایج است (نه انتقال اعتبار)، فقط تگ نو ایندکس بگذار.
تگ نو ایندکس و فایل robots.txt هر دو ابزار کنترل دیدهشدناند، اما هر کدام در سطح متفاوتی از فرایند «Crawl → Index → Rank» کار میکنند.canonical هم بهجای پنهان کردن، به گوگل جهت میدهد که «کدام نسخه» را اصلی بداند.به یاد داشته باش:سئو مثل شطرنج است؛ هر مهره (noindex، canonical، robots.txt) نقش خودش را دارد. اگر شاه را با سرباز عوضی بگیری، بازی را میبازی!
روشهای پیادهسازی تگ noindex (کدها و نکات عملی)
حالا که فهمیدیم تگ نو ایندکس دقیقاً چه کاری انجام میدهد، وقتشه با پیادهسازیاش آشنا شویم.در کل، سه روش اصلی برای گفتن «اینو ایندکس نکن» به گوگل وجود دارد:
- Meta Robots Tag در HTML
- X-Robots-Tag در Header سرور (HTTP Header)
- تنظیمات CMS مثل وردپرس یا افزونههای سئو
بیایید هر کدام را با مثال واقعی بررسی کنیم.
۱. تگ Meta Robots در HTML
رایجترین و سادهترین روش است. کافیست در قسمت <head> صفحه، این تگ را قرار دهید:
<meta name=”robots” content=”noindex, follow”>
توضیح پارامترها:
- noindex → گوگل این صفحه را در نتایجش ذخیره نکند.
- follow → لینکهای داخل صفحه را دنبال کن و ارزش لینکها را عبور بده.
اگر میخواهید دقیقتر باشید، میتوانید موتور جستجو را مشخص کنید:<meta name=”googlebot” content=”noindex, follow”> <meta name=”bingbot” content=”noindex, follow”>
نکته حرفهای:
حتی اگر مقدار follow را ننویسید، گوگل معمولاً فرض میکند که لینکها باید دنبال شوند، اما برای وضوح و جلوگیری از سوءبرداشت، همیشه بنویسید. مثال واقعی:فرض کن صفحهی تشکر از خرید در سایت فروشگاهت اینه:https://yourdomain.com/thank-you/در کد HTML اون صفحه در بخش <head> میذاری:<head> <title>تشکر از خرید شما</title> <meta name=”robots” content=”noindex, follow”> </head>

نتیجه:
کاربر پس از خرید صفحه را میبیند، گوگل آن را میبیند، لینکهای داخلی را دنبال میکند، اما خودش را از نتایج حذف میکند.تمیز، حرفهای و دقیق.
۲. X-Robots-Tag در Header سرور (برای فایلها یا کنترل پیشرفته)
گاهی صفحاتی داری که فایل HTML نیستند (مثلاً PDF، DOCX، ZIP یا حتی تصویر).در این حالت تگ Meta داخل آنها معنی ندارد.راهحل؟ از هدر HTTP استفاده کن، یعنی همون چیزی که سرور قبل از ارسال محتوا به مرورگر میفرسته.
نمونه برای Apache (.htaccess):
<FilesMatch “\.(pdf|docx)$”> Header set X-Robots-Tag “noindex, noarchive, follow” </FilesMatch>در این مثال:
- تمام فایلهای PDF و DOCX با این هدر به گوگل ارسال میشوند.
- یعنی: ایندکس نکن، در نتایج نگه ندار (noarchive)، ولی لینکهای داخلش را دنبال کن.
نمونه برای Nginx:
location ~* \.(pdf|docx)$ { add_header X-Robots-Tag “noindex, follow”; }
با این روش، بدون نیاز به تغییر تکتک فایلها، در سطح سرور به گوگل میگویی که این نوع فایلها وارد ایندکس نشوند.این کار برای سایتهای بزرگ یا دایرکتوریهای خاص (مثلاً /internal-media/) فوقالعاده است.
تست صحت کارکرد (برای اهل فنی!):
اگر خواستی مطمئن شوی هدر بهدرستی کار میکند، در مرورگر یا ابزار خط فرمان از دستور curl استفاده کن:curl -I https://yourdomain.com/example.pdf و در خروجی باید ببینی:X-Robots-Tag: no index, follow.اگر این خط وجود داشت، یعنی دستورت درست پیاده شده
۳. تنظیمات noindex در وردپرس (بدون کدنویسی)
اگر از وردپرس استفاده میکنی، خبر خوب اینکه نیازی نیست دستی به <head> یا سرور دست بزنی.افزونههای معروف مثل Yoast SEO یا Rank Math این قابلیت را دارند.
در Yoast SEO:
- وارد صفحه یا نوشتهی مورد نظر شو.
- پایین صفحه، در بخش “Advanced” تنظیمات Yoast را باز کن.
- گزینهی Allow search engines to show this post in search results? را روی No بگذار.
Yoast بهطور خودکار تگ <meta name=”robots” content=”noindex, follow”> را به <head> اضافه میکند.
در Rank Math:
- بخش Advanced → Robots Meta
- گزینهی No Index را فعال کن.
- اگر خواستی لینکها هم دنبال نشوند، تیک No Follow را هم بزن.
نکته کاربردی:در تنظیمات عمومی وردپرس هم گزینهای هست به نام:“از موتورهای جستجو درخواست کن که محتوای سایت را ایندکس نکنند.”(در مسیر تنظیمات > خواندن)اما این گزینه سایت را بهطور کلی no index میکند. برای محیطهای آزمایشی خوب است، نه برای سایت فعال.
۴. noindex در سطح دستهبندیها و برچسبها (Taxonomies)
یکی از بزرگترین اشتباهات در سایتهای محتوایی و فروشگاهی این است که دستهبندیها و برچسبها بدون هدف سئو فعال میشوند و دهها صفحهی خالی یا تکراری وارد ایندکس گوگل میکنند.بهترین کار:
- اگر دستهبندی محتوای مفید دارد (مثلاً توضیح یونیک، لینکهای هدفمند، FAQ)، بگذار ایندکس بماند.
- اگر فقط لیستی از پستهاست بدون محتوای مجزا، با تگ نو ایندکس از ایندکس خارجش کن.
در Yoast یا Rank Math، این تنظیم برای تمام taxonomyها (category، tag، author) بهصورت گروهی قابل انجام است.
۵. کنترل no index از طریق Sitemap یا Search Console (غیرمستقیم)
گاهی میخواهی از طریق سرچ کنسول مطمئن شوی صفحهای no index شده یا خیر.راهش ساده است:
- وارد Google Search Console شو.
- از بخش Inspect URL آدرس را بررسی کن.
- اگر وضعیت این باشد:
Excluded by ‘noindex’ tag
یعنی همه چیز درست کار میکند.اگر هنوز ایندکس است، شاید گوگل هنوز صفحه را Crawl نکرده باشد یا دستور را نخوانده.برای سرعت بیشتر میتوانی روی دکمهی Request Indexing بزنید تا گوگل صفحه را دوباره ببیند (حتی اگر در واقع قرار نیست ایندکس شود، این کار باعث میشود دستور تگ نو ایندکس سریعتر اعمال شود).
۶. ترکیب هوشمندانه noindex با دستورات دیگر
گاهی فقط حذف از ایندکس کافی نیست. شاید بخواهی نمایش توضیحات متا یا تصویر هم کنترل شود.در این حالت، میتوانی دستورات اضافی را به تگ robots اضافه کنی:
| دستور | توضیح | کاربرد |
| noindex | حذف از نتایج جستجو | جلوگیری از ایندکس |
| nofollow | دنبال نکردن لینکها | صفحات محرمانه یا بیاهمیت |
| noarchive | جلوگیری از ذخیره نسخه کششده در نتایج | صفحات حساس |
| nosnippet | حذف توضیحات و ریچ اسنیپت در نتایج | جلوگیری از نمایش داده اضافی |
| noimageindex | جلوگیری از ایندکس تصاویر صفحه | سایتهای دارای تصاویر خصوصی |
| max-snippet:-1 | کنترل طول اسنیپت | برای مدیریت نمایش در نتایج |
مثلاً ترکیب حرفهای:<meta name=”robots” content=”noindex, noarchive, follow, nosnippet”>.نکته امنیتی مهم:اگر واقعاً نمیخواهی محتوایی توسط گوگل دیده شود (مثلاً فایلهای محرمانه یا اطلاعات مشتری)، به no index اکتفا نکن.چون ربات ممکن است از طریق لینکهای خارجی یا حتی سایتمپ آن را پیدا کند.در این موارد:
- دسترسی را با رمز (HTTP Authentication) محدود کن.
- از robots.txt و تنظیمات سرور استفاده کن.
- یا فایلها را از دامنهی ایندکسپذیر جدا نگه دار (Subdomain خصوصی).
خطاهای رایج در پیادهسازی noindex
| خطا | توضیح | نتیجه |
| ترکیب با Disallow | ربات صفحه را نمیبیند، دستور no index را نمیخواند | صفحه ممکن است در نتایج بماند |
| تگ در جای اشتباه (خارج از <head>) | تگ نادیده گرفته میشود | بدون تأثیر |
| noindex در Sitemap باقی مانده | تضاد سیگنالها | هشدار در سرچ کنسول |
| Cache CDN فعال | دستور قدیمی تحویل داده میشود | تأخیر در حذف از نتایج |
| اشتباه در Case حساس (NoIndex بهجای no index) | گوگل ممکن است نادیده بگیرد | بدون اثر |
تگ نو ایندکس، اگر درست پیاده شود، مثل دکمهی «حذف ایمن» برای موتور جستجو عمل میکند.نه مثل delete که همهچیز را از بین ببرد، نه مثل ignore که هیچ کاری نکند؛ دقیق و هدفمند.به زبان سادهتر:”noindex یعنی: من این صفحه رو برای خودم میخوام، نه برای دنیا!”ترفندها و تعاملات پیشرفته noindex.(noindex + indexifembedded + nosnippet و ترکیبهای حرفهای دیگر)
وقتی تازه با no index آشنا میشی، فکر میکنی فقط یه دستور ساده است: «اینو ایندکس نکن».اما وقتی چند سال در دنیای سئو کار کنی، میفهمی که تگ نو ایندکس در ترکیب با سایر دستورها، میتونه تبدیل بشه به یه ابزار بسیار دقیق برای مدیریت حضور محتوای سایت در نتایج گوگل. همونطور که یه جراح با اسکالپل میلیمتری کار میکنه، نه با چکش! بیایید ببینیم چطور میشه از این ابزار بهصورت حرفهایتر استفاده کرد.
۱. ترکیب no index با indexifembedded
یکی از ویژگیهای کمتر شناختهشده و بسیار هوشمندانهی گوگل، دستور indexifembedded هست.فرض کن یک صفحه داری که خودش نباید در نتایج گوگل ظاهر بشه، اما محتواش داخل صفحات دیگه از سایتت به صورت Embed (جاسازی) نمایش داده میشه.مثلاً:
- یک ویدیو یا نمودار آموزشی داری که با iframe در چند مقاله استفاده شده،
- یا یک بخش «پرسش و پاسخ» که در چند صفحه embed میکنی.
اگر کل اون صفحه رو noindex کنی، گوگل دیگه نمیتونه محتوای جاسازیشده رو در نتایج سایر صفحات ایندکس کنه.اینجاست که دستور ترکیبی indexifembedded به دادت میرسه.
مثال:<meta name=”robots” content=”noindex, indexifembedded”>
توضیح ساده:
- noindex: خود صفحه نباید در نتایج بیاد.
- indexifembedded: اگر محتوای این صفحه در جایی embed شده، اون بخش میتونه ایندکس بشه.
به زبان سادهتر:مثل این میمونه که به گوگل بگی:«خودم رو قایم کن، ولی اگه بخشی از من داخل صفحه دیگهای بود، اون رو نشون بده!»موارد کاربرد واقعی:
- صفحات مخصوص embed ویدیو، نقشه، یا گالری.
- محتوای تکراری در چند مقاله (مثل بلوک “نکات ایمنی”) که میخوای فقط از طریق صفحهی اصلیش ایندکس بشه.
- صفحات جداگانهای که فقط برای سرویس embed ساخته شدن.
این ترکیب یکی از ابزارهای کلیدی برای مدیریت duplicate content در سایتهای بزرگ و پلتفرمهای چندرسانهای.
۲. noindex در کنار nosnippet (حذف توضیحات از نتایج)
گاهی نمیخوای صفحه رو از نتایج حذف کنی، اما نمیخوای گوگل توضیحاتش (Meta Description یا متن محتوا) رو در نتایج نشون بده.در این حالت، دستور nosnippet وارد میشه.<meta name=”robots” content=”noindex, nosnippet”>
اما دقت کن:اگر noindex باشه، در هر صورت صفحه از نتایج حذف میشه!پس این ترکیب در عمل معمولاً معنی نداره.اما اگر بخوای فقط اسنیپت حذف بشه، از nosnippet به تنهایی استفاده کن:<meta name=”robots” content=”nosnippet”>
کاربردش:
- جلوگیری از نمایش توضیحات محرمانه یا بخشی از محتوا در نتایج جستجو.
- مخصوصاً برای سایتهایی که متن داخل صفحه قراردادی یا اختصاصی دارن.
۳. ترکیب noindex با noimageindex
گاهی محتوای صفحه مفید است، اما نمیخواهی تصاویرش در Google Images نمایش داده شوند (مثلاً عکسهای اختصاصی محصولات، افراد، یا دارایی برند).در این حالت از دستور زیر استفاده کن:<meta name=”robots” content=”noindex, noimageindex”>
اما دقت کن:
اگر کل صفحه را no index کردی، تصاویرش هم معمولاً از ایندکس حذف میشوند.بنابراین noimageindex زمانی بیشتر کاربرد دارد که صفحه ایندکس شود ولی فقط تصاویرش ایندکس نشوند:<meta name=”robots” content=”index, noimageindex”>
نتیجه:
- خود صفحه در نتایج هست.
- ولی عکسهاش در بخش Google Images دیده نمیشن.
۴. ترکیب با noarchive و max-snippet
این ترکیب برای کنترل نحوه نمایش نتایج در SERP استفاده میشود.
<meta name=”robots” content=”noindex, noarchive, max-snippet:-1″>
توضیح:
- noarchive → نسخهی کششده در گوگل نمایش داده نشود.
- max-snippet:-1 → اجازهی نمایش کامل اسنیپت در صورت ایندکسشدن (مقدار منفی یعنی نامحدود).
البته وقتی صفحه no index باشد، این مقادیر مستقیماً روی نمایش تأثیر ندارند، اما گوگل ممکن است برای صفحات مشابه یا canonical شده سیگنالهای این دستورات را لحاظ کند.
۵. noindex در هدر X-Robots همراه با پارامترهای خاص
برای فایلهایی مثل PDF، JSON یا XML که Meta Tag ندارند، میتوانی از ترکیبهای خاص در سطح سرور استفاده کنی:
Apache
<FilesMatch “\.pdf$”> Header set X-Robots-Tag “noindex, noarchive, nosnippet” </FilesMatch>
Nginx
location ~* \.pdf$ { add_header X-Robots-Tag “noindex, noarchive”; }
کاربرد حرفهای:
- برای فایلهای قرارداد، جزوات، گزارشها یا فایلهای آموزشی پولی که نباید در گوگل ظاهر بشن.
- برای صفحات XML مثل گزارشهای ساختار داده یا Exportهای سیستم.
۶. رفتار گوگل با دستورات ترکیبی
گوگل همیشه در تفسیر دستورات robots از اصل «منع ایندکس» پیروی میکنه؛ یعنی اگر چند دستور متناقض بدهی، اولویت با no index است.مثلاً در این ترکیب:<meta name=”robots” content=”noindex, follow, nosnippet, noimageindex”>

گوگل:
- صفحه را ایندکس نمیکند (noindex).
- لینکها را دنبال میکند (follow).
- هیچ اسنیپت یا تصویر از آن نمایش نمیدهد (nosnippet, noimageindex).
پس اگر چند دستور با هم آمد، همیشه بدون استرس بدان:“noindex حرف آخر را میزند!”
۷. نکته پیشرفته: تفاوت دستورهای Global و Engine-specific
میتوانی دستورهای no index را برای کل موتورهای جستجو بنویسی (robots)یا فقط برای یک موتور خاص، مثلاً Googlebot یا Bingbot.مثال:<meta name=”robots” content=”noindex, follow”> <meta name=”googlebot” content=”index, follow”>در این حالت، دستور دوم فقط برای گوگل اعمال میشود و اولی برای بقیه موتورهای جستجو.ولی پیشنهاد حرفهای این است که همیشه سیاست یکنواخت داشته باشی، مگر در تستهای خاص.
نکته طلایی استراتژیک:
اگر محتوای شما در پلتفرمهای مختلف (وباپ، سابدامین، Embed) منتشر میشود، no index + indexifembedded یکی از بهترین ترکیبهای ممکن است.چون به گوگل کمک میکند بفهمد:
- «اصل محتوا را در صفحهی مادر ایندکس کن، نه در نسخهی Embed.»
بهاینترتیب، از مشکل Duplicate Embed Content خلاص میشوی و سئوی محتوای اصلیات هم تقویت میشود.
۸. نمونهی کامل ترکیب حرفهای (پیشنهاد برای سایتهای بزرگ)
<meta name=”robots” content=”noindex, follow, indexifembedded, noarchive”> <meta name=”googlebot” content=”noindex, follow, indexifembedded, max-snippet:-1″>
- صفحه ایندکس نمیشود.
- لینکهای داخلی دنبال میشوند.
- اگر در صفحات دیگر Embed شد، محتوایش ایندکس میشود.
- نسخه کششده در نتایج نمایش داده نمیشود.
یک ترکیب تمیز و بینقص برای صفحات سیستمی یا محتوای قابلنمایش در قالب iframe.تگ نو ایندکس، برخلاف ظاهر سادهاش، میتواند مثل یک ابزار دقیق سئو عمل کند؛ به شرط آنکه با دیگر دستورات درست ترکیب شود.اگر بخواهیم خلاصه کنیم:
- برای حذف ساده از نتایج → no index, follow
- برای کنترل فایلها در سرور → X-Robots-Tag
- برای embedهای داخلی → no index, indexifembedded
- برای حذف تصاویر از نتایج → index, noimageindex
- برای جلوگیری از کششدن → noarchive
و یادت باشد:«noindex جاروبرقی نیست که هر چی هست جمع کنه؛ جارو دقیقِ گوشههای سئوئه!»
چه صفحاتی را باید noindex کنیم؟
(تصمیمنامه حرفهای برای کنترل ایندکس سایت)وقتی صحبت از بهینهسازی ایندکس گوگل میشه، هدف فقط “افزایش تعداد صفحات ایندکسشده” نیست؛ هدف بهبود کیفیت ایندکسه.چرا؟ چون گوگل مثل یک کتابخانهی هوشمنده؛ اگر هزار جلد کتاب بیارزش بهش بدی، در پیدا کردن آثار مهمت گیج میشه.پس گاهی بهترین کار اینه که بعضی صفحات رو از چرخه ایندکس بیرون بندازی تا کیفیت بقیه بالا بره و این دقیقاً کار تگ نو ایندکس.به قول معروف:«همهچیز برای همهکس خوب نیست؛ در سئو هم، هر صفحهای برای گوگل ساخته نشده!»
۱. صفحات سیستمی و خصوصی (System & Utility Pages)
این دسته از صفحات معمولاً برای کاربر داخل سایت مفیدند، اما هیچ ارزش جستجویی ندارند.نمونهها:
- صفحه ورود (Login)
- صفحه ثبتنام یا عضویت (Register / Sign-up)
- صفحه سبد خرید (Cart)
- صفحه پرداخت و تأیید سفارش (Checkout / Thank You)
- صفحه تنظیمات کاربری یا داشبورد
دلیل استفاده از noindex:این صفحات برای کاربران ثبتنامشده یا مشتریان خاص ساخته شدن، نه برای کاربرانی که از گوگل میان.نمایش اونها در نتایج باعث گیجی و نرخ پرش (Bounce Rate) بالا میشه. پیشنهاد:<meta name=”robots” content=”noindex, follow”>
۲. نتایج جستجوی داخلی (Site Search Results Pages)
یکی از اشتباهات بزرگ در سایتهای فروشگاهی و محتوایی، ایندکس شدن صفحات جستجوی داخلی است.مثلاً آدرسهایی مثل:/search?q=گوشی+شیائومی .این صفحات معمولاً محتوای تکراری دارن، مرتب تغییر میکنن و هیچ هدف جستجویی مشخصی از دید گوگل ندارن.چرا باید نو ایندکس کنیم؟
- محتوای پویا و متغیر دارن → ایندکس بیثبات ایجاد میکنن.
- معمولاً باعث Duplicate Content میشن.
- Crawl Budget رو هدر میدن.
راهحل:<meta name=”robots” content=”noindex, follow”>در عین حال، میتونی این صفحات رو از Sitemap هم حذف کنی.
۳. صفحات تکراری یا پارامتردار (URL Parameters)
اگر سایتت پارامترهایی مثل sort، filter، utm یا session داره، معمولاً هر ترکیب پارامتر، یک URL جدید تولید میکنه.مثل:/products?color=red&sort=price.گوگل ممکنه همه این نسخهها رو ایندکس کنه و محتوای تکراری بسازه.چرا باید noindex کنیم؟

- بهجای تقویت نسخه اصلی، رتبهگیری بین صفحات تکراری تقسیم میشه.
- Crawl Budget از بین میره.
پیشنهاد حرفهای:
- برای نسخه اصلی canonical بگذار.
- برای نسخههای پارامتردار no index استفاده کن.
۴. آرشیوهای نویسنده، برچسب و تاریخ (Tag / Author / Date Archives)
در سایتهای وبلاگی یا خبری، آرشیوها معمولاً محتوای تکراری تولید میکنن.مثلاً برگهی نویسنده همهی مقالات اون فرد رو لیست میکنه، اما محتوای جدیدی نداره.
چه زمانی باید no index کنیم؟
- اگر صفحهی آرشیو هیچ متن یا توضیح یونیکی نداره.
- اگر ساختار محتوایی ضعیفه و فقط لینک پستهاست.
در وردپرس:در افزونهی Yoast SEO یا Rank Math بهراحتی میتونی همهی صفحات Tag و Author رو no index کنی.
۵. صفحات موقت و تستی (A/B Testing, Staging)
اگر روی دامنه اصلیت تست طراحی، محتوا یا سیستم داری، اون صفحات رو نباید در نتایج ببینه.صفحات Stage یا نسخههای موقت معمولاً محتوای تکراری دارن و ایندکس شدنشون میتونه فاجعهبار باشه!
راهحل:
- در فایل robots.txt دسترسی Crawl رو ببند.
- در متای صفحه تگ نو ایندکس بگذار تا اگر احیاناً گوگل دید، ایندکس نکنه.
۶. صفحات تشکر و تأیید عملیات (Thank You / Confirmation Pages)
بعد از خرید یا ثبت فرم، کاربر به صفحه تشکر میره.این صفحه معمولاً با لینک خاص یا پارامتر session در دسترسه.مشکل:اگر ایندکس بشه، افراد غریبه ممکنه از گوگل مستقیم برن به صفحه «تشکر از خرید!» بدون اینکه خریدی انجام داده باشن. راهحل:<meta name=”robots” content=”noindex, follow”>در عین حال، اگر این صفحه لینکهای راهنما یا CTA داره، با follow حفظش کن.
۷. صفحات تکراری از دید محتوا (Duplicate & Thin Content)
گاهی صفحاتی داریم که فقط ۱۰۰ کلمه متن دارن یا محتوای مشابه صفحات دیگهان.گوگل به این صفحات ارزش سئویی نمیده و حتی ممکنه نمرهی کیفیت کلی دامنهات رو پایین بیاره.
نمونهها:
- صفحات محصولات فروختهشده (Out of Stock).
- صفحات با توضیحات کوتاه و بدون تصویر.
- صفحات خبر کوتاه با چند خط متن مشابه منابع دیگر.
پیشنهاد:اگر امکان تقویت محتوا نیست → no index.اگر میتونی محتوا رو گسترش بدی → محتوا رو ارتقا بده و ایندکسش نگه دار.
۸. صفحات خصوصی یا مخصوص کاربران ثبتنامشده
در سایتهای آموزشی، فروشگاهی یا شرکتی گاهی بخشی از محتوا فقط برای کاربران خاصه (مثلاً درسهای ویژه، داشبورد مشتری).نمایش این صفحات در نتایج گوگل نهتنها بیفایده است، بلکه ممکنه باعث لو رفتن اطلاعات بشه.
بهترین روش:
- ترکیب تگ نو ایندکس با محدودیت دسترسی (Login یا Token).
- اگه محتوای خیلی حساسه → اصلاً اجازه Crawl نده (Disallow).
۹. صفحات خطا (404، 403، 500) و صفحات خالی
اگر صفحهای خطای 404 یا 500 میده اما تگ noindex نداره، گوگل ممکنه اون رو در نتایج نگه داره تا زمانی که مطمئن بشه حذف شده.بهتره این صفحات بهصورت خودکار نو ایندکس بشن یا کد وضعیت HTTP درست برگردونن.نکته:در CMS یا سرور تنظیم کن که تمام صفحات خطا شامل تگ زیر باشن:<meta name=”robots” content=”noindex, nofollow”>
۱۰. صفحات تبلیغاتی یا کمپینهای فصلی (Campaign / Promo Pages)
صفحات تخفیف یا رویداد (مثل فروش جمعه سیاه) معمولاً عمر کوتاهی دارن.بعد از اتمام کمپین، وجودشون در ایندکس فقط باعث پرترافیک شدن دادههای قدیمی میشه.
پیشنهاد:
- بعد از پایان کمپین → صفحه را no index کن یا به صفحه جدید Redirect بده.
- برای کمپینهای آینده ساختار قابلتکرار طراحی کن.
جدول تصمیمگیری حرفهای برای تگ نو ایندکس:
| نوع صفحه | ایندکس شود؟ | تگ پیشنهادی | توضیح |
| صفحه لاگین / عضویت | خیر | noindex, follow | کاربردی داخلی دارد |
| صفحه تشکر از خرید | خیر | noindex, follow | محتوای موقتی |
| صفحات جستجوی داخلی | خیر | noindex, follow | تولید محتوای تکراری |
| صفحات آرشیو برچسب / نویسنده | بستگی دارد | noindex اگر محتوای یونیک ندارد | جلوگیری از تکرار |
| صفحات پارامتردار (utm, sort) | خیر | noindex, follow | به نسخه اصلی canonical بده |
| صفحات تست یا Stage | خیر | noindex + Disallow | جلوگیری از ایندکس آزمایشی |
| صفحات محصولات فروختهشده | بستگی دارد | noindex یا Redirect | اگر بازگشت ندارد |
| صفحات آموزشی پریمیوم (فقط اعضا) | خیر | noindex, nofollow | اطلاعات خصوصی |
| صفحات کمپین منقضیشده | خیر | noindex, follow | یا Redirect 301 به صفحه جدید |
نکته کاربردی از تجربهی میدانی:
گاهی مدیر سایتها از ترس «حذف شدن از گوگل» جرأت استفاده از no index رو ندارن!اما واقعیت اینه که no index نهتنها مضر نیست، بلکه اگر هوشمندانه استفاده بشه، سئوی کلی دامنه رو تقویت میکنه.به بیان ساده:“ایندکس کمتر، کیفیت بیشتر.”وقتی فقط صفحات با ارزش بالا ایندکس باشن، نرخ کلی CTR و تعامل کاربر در سرچ کنسول بهتر میشه، چون گوگل فقط صفحات واقعی و هدفمند شما رو نمایش میده.
پایش، تست و تحلیل تگ نو ایندکس در Google Search Console
(چطور مطمئن شویم no index درست کار کرده؟)وقتی تگ نو ایندکس رو در صفحات مختلف سایت قرار میدی، کار تموم نمیشه!در واقع تازه وارد فاز دوم میشی . نظارت و تحلیل.گوگل ممکنه چند ساعت تا چند روز زمان ببره تا دستور no index رو پردازش کنه.اگر نظارت نکنی، ممکنه صفحات مهمت به اشتباه از ایندکس حذف بشن یا صفحات بیارزش هنوز در نتایج بمونن.پس بیایید مرحله به مرحله بررسی کنیم :
1 .بررسی دستی با ابزار URL Inspection
سادهترین روش برای تست تاثیر no index اینه که از ابزار Inspect URL در سرچ کنسول استفاده کنی.مراحل:
- وارد Google Search Console شو.
- در بالای صفحه، آدرس دقیق صفحه مورد نظر رو وارد کن.
- روی Enter بزن تا گوگل وضعیت صفحه رو نمایش بده.
اگر تگ نو ایندکس درست تنظیم شده باشه، باید یکی از پیامهای زیر رو ببینی:Excluded by ‘noindex’ tag یا Submitted URL marked ‘noindex’. تفسیر پیام: یعنی گوگل دستور no index رو دیده و صفحه رو از ایندکس خارج کرده — همهچیز درست پیش رفته.
۲ .استفاده از Coverage Report (گزارش پوشش صفحات)
برای بررسی گستردهتر کل سایت، از بخش Coverage یا در نسخه جدید سرچ کنسول از Pages report استفاده کن.مسیر:Search Console → Indexing → Pages.در اینجا دستهبندیهای مختلفی از وضعیت ایندکس صفحات میبینی، از جمله:
- Indexed — صفحه در ایندکس است.
- Excluded by ‘no index’ tag — صفحه با موفقیت حذف شده.
- Crawled – currently not indexed — گوگل صفحه را دیده اما هنوز تصمیم نگرفته ایندکس کند.
- Discovered – currently not indexed — صفحه پیدا شده اما هنوز Crawl نشده.
اگر در گزارش Coverage ببینی تعداد صفحاتی که با وضعیت ‘Excluded by no index’ مشخص شدن، دقیقاً با استراتژیات همخوانی دارن، یعنی تنظیمات درست عمل کرده.
نکته حرفهای:
اگر صفحات مهم در این دسته دیده شدن، شاید اشتباهی در تگگذاری وجود داره.
۳ .زمان تأثیر تگ نو ایندکس چقدره؟
تأثیر تگ نو ایندکس به فرکانس خزش (Crawl Frequency) بستگی داره.در دامنههای فعال، گوگل معمولاً ظرف ۲۴ تا ۷۲ ساعت تغییرات رو تشخیص میده.اما در سایتهای کمفعالیت یا تازهکار ممکنه ۱ تا ۲ هفته طول بکشه.
ترفند سرعتدهی:
- روی دکمهی Request Indexing بزن (حتی برای صفحات نو ایندکس).
این کار باعث میشه ربات گوگل سریعتر بیاد و دستور no index رو ببیند. - اگر CDN یا Cache فعال داری، قبلش مطمئن شو نسخهی کششده قدیمی نباشه.
۴ .گزارشهای مفید در Coverage برای بررسی تگ نو ایندکس
| وضعیت در گزارش | معنی | اقدام لازم |
| Excluded by ‘noindex’ tag | تگ به درستی اعمال شده | هیچ اقدامی لازم نیست |
| Submitted URL marked ‘noindex’ | صفحه در سایتمپ بوده اما no index شده | از سایتمپ حذفش کن |
| Crawled – currently not indexed | گوگل صفحه را دیده ولی فعلاً ایندکس نکرده | بررسی کیفیت محتوا |
| Blocked by robots.txt | دستور Disallow مانع از خزش شده | اگر هدف حذف از ایندکس است، فقط no index بگذار |
| Alternate page with proper canonical tag | صفحه با canonical حذف شده | مشکلی نیست |
۵ .بررسی گروهی صفحات با ابزارهای آنالیز سئو
اگر سایت بزرگ داری، بررسی تکبهتک صفحات وقتگیره.در این حالت از ابزارهایی مثل Screaming Frog SEO Spider یا Sitebulb استفاده کن تا همه صفحات رو یکجا آنالیز کنن.
در Screaming Frog:
- سایتت رو Crawl کن.
- از ستون “Indexability” و “Meta Robots” استفاده کن.
- ببین کدوم صفحات تگ noindex دارن و وضعیت ایندکسشون درسته یا نه.
خروجی مفید:
- ستون “Indexability” = Non-Indexable (noindex) → یعنی درست کار کرده.
- اگر “Blocked by robots.txt” دیدی، بدون که دستور no index اصلاً خونده نمیشه.
۶. بررسی فایلهای خاص (PDF, DOC, etc.)
اگر از X-Robots-Tag برای فایلها استفاده کردی، با دستور زیر در مرورگر تست کن.curl -I https://yourdomain.com/example.pdf.در خروجی، باید ببینی:X-Robots-Tag: no index, follow اگر نبود، یعنی تنظیمات سرور هنوز اعمال نشده.
۷. شناسایی تضاد بین تگها و سیگنالها
گاهی صفحهای همزمان noindex tag و canonical به یک URL دیگر داره.در این حالت، گوگل معمولاً canonical را نادیده میگیرد چون no index اولویت دارد.پس حتماً در ابزار Inspection بررسی کن که فقط یکی از این دو وجود داشته باشه:
- اگر هدف «حذف از نتایج» است → فقط no index.
- اگر هدف «ادغام سیگنالها» است → فقط canonical.
۸. بررسی در نتایج واقعی گوگل (تست میدانی)
اگر میخواهی مطمئن شی صفحهای واقعاً حذف شده، میتونی از اپراتورهای جستجو استفاده کنی:site:yourdomain.com/page-url.اگر هیچ نتیجهای نیومد → صفحه از ایندکس حذف شده.اگر هنوز میبینی → یا کش قدیمی نمایش داده میشه، یا گوگل هنوز تغییر رو نخوانده.
در این حالت، پیشنهاد میشه:
- نسخهی کش گوگل را Request Removal کنی (از Search Console → Removals → Temporary Removals).
- یا منتظر خزش مجدد بمانی.
۹. KPIها و تحلیل سئویی بعد از اعمال no index
برای تحلیل تأثیر استراتژیک no index، این شاخصها رو در Search Console زیر نظر بگیر:
| شاخص | تغییر مطلوب | توضیح |
| تعداد صفحات Excluded by no index | افزایش کنترلشده | یعنی صفحات بیارزش حذف شدن |
| Impressions کلی سایت | ممکن است کمی کاهش یابد | طبیعی است چون صفحات غیرهدف حذف شدهاند |
| CTR صفحات باقیمانده | افزایش | چون نتایج دقیقتر و هدفمندترند |
| Crawl Budget Usage | بهبود (پایینتر) | ربات زمانش را روی صفحات ارزشمند صرف میکند |
| Index Coverage Errors | کاهش | چون صفحات غیرقابلنمایش از گزارش خطا حذف میشوند |
اگر این شاخصها در جهت درست حرکت کنند، یعنی استراتژی نو ایندکس موفق بوده.
۱۰. رفع سریع خطاها و هشدارها
اگر در گزارش Coverage دیدی گوگل برای صفحهای که باید ایندکس باشد پیام”Excluded by ‘noindex’ tag”داده، یعنی تگی اشتباه مانده یا پلاگین سئو بهصورت خودکار آن را فعال کرده.
در وردپرس:
Yoast → Advanced → Robots Meta → گزینه “?Allow search engines to show this post in search results” را روی Yes بگذار.در Rank Math:از بخش Advanced → Robots Meta → گزینه “No Index” را خاموش کن.سپس روی Request Indexing بزن تا گوگل مجدد بررسی کند.
- تگ نو ایندکس فقط زمانی مؤثر است که ربات بتواند صفحه را Crawl کند.
- همیشه بعد از اعمالش، از Search Console یا Screaming Frog بررسی کن.
- صفحات نو ایندکس را از Sitemap حذف کن تا گوگل گیج نشود.
- KPIهای کلیدی (CTR، Crawl Budget، Impressions) را در طول زمان پایش کن.
به بیان ساده:«noindex مثل رژیم گرفتن برای ایندکس گوگل است؛ اگر با برنامه پیش بری، سبک و سالم میشی، ولی اگه بیحساب و کتاب بری، انرژیات کم میشه!»

سؤالات متداول درباره تگ no index
۱. تگ نو ایندکس دقیقاً چه کاری انجام میدهد؟
noindex tag به موتور جستجو (مثلاً Googlebot) میگوید که این صفحه را در نتایج جستجو نمایش نده.اما ربات همچنان میتواند صفحه را Crawl کند، محتوایش را بخواند و لینکهایش را دنبال کند — بهویژه اگر از no index, follow استفاده کنی.خلاصه: no index یعنی “برو ببین، ولی نشون نده.”
۲. تفاوت no index با robots.txt در چیست؟
- robots.txt جلوی خزش (Crawl) را میگیرد، اما نمیتواند جلوی نمایش (Index) را بگیرد.
- no index اجازه خزش میدهد ولی جلوی نمایش را میگیرد.
بنابراین اگر هدف تو جلوگیری از دیدهشدن صفحه در نتایج است، نو ایندکس انتخاب درستتر است.اما اگر نمیخواهی ربات اصلاً وارد صفحه شود (مثلاً محتوای خصوصی داری)، از robots.txt یا احراز هویت (Authentication) استفاده کن.
۳. اگر صفحهای را noindex کنم، لینکهایش از بین میرود؟
خیر تا زمانی که مقدار follow در تگ باشد، لینکها همچنان دنبال میشوند و اعتبارشان منتقل میشود.<meta name=”robots” content=”noindex, follow”>اما اگر از nofollow استفاده کنی، گوگل معمولاً لینکهای داخلی را دنبال نمیکند (یا با تأخیر).
۴. چقدر طول میکشد تا صفحه noindex از نتایج حذف شود؟
معمولاً بین ۲۴ تا ۷۲ ساعت بعد از Crawl مجدد صفحه.اما این زمان بستگی به فرکانس خزش (Crawl Frequency)، اعتبار دامنه و ترافیک صفحه دارد.برای تسریع فرایند، در Search Console روی دکمهی Request Indexing کلیک کن تا گوگل سریعتر صفحه را ببیند و دستور نو ایندکس را اعمال کند.
۵. آیا باید صفحات noindex را از Sitemap حذف کنم؟
بله زیرا Sitemap به گوگل میگوید “این صفحات را ایندکس کن”.وقتی در همان صفحات نو ایندکس داری، سیگنال متناقض ارسال میکنی.بنابراین بهتر است صفحات no index در Sitemap نباشند.
۶. آیا میتوان از canonical و noindex همزمان استفاده کرد؟
توصیه نمیشود وقتی canonical و no index را با هم بگذاری، گوگل سردرگم میشود:
- canonical میگوید “اینو در نظر بگیر و ایندکس کن”
- no index میگوید “اینو نادیده بگیر”
در این حالت، گوگل معمولاً نو ایندکس را ترجیح میدهد و canonical را نادیده میگیرد.اگر میخواهی محتوای مشابه را به نسخهی اصلی منتقل کنی، فقط canonical بگذار.اگر میخواهی حذف شود، فقط نو ایندکس.
۷. آیا گوگل همچنان نو ایندکس را برای فایلهای غیر HTML (PDF, DOCX, JPG) میپذیرد؟
بله اما با روش X-Robots-Tag در Header سرور.مثلاً برای فایل PDF در Apache:<FilesMatch “\.pdf$”> Header set X-Robots-Tag “noindex, follow” </FilesMatch>به این ترتیب، فایل در نتایج جستجو نمایش داده نمیشود، اما همچنان لینکهایش (اگر داشته باشد) قابلردیابیاند.
۸. آیا تگ no index جلوی خزش گوگل را هم میگیرد؟
خیر تگ no index فقط جلوی ایندکس شدن را میگیرد، نه خزش را.اگر میخواهی اصلاً صفحه دیده نشود، از robots.txt (Disallow) یا رمز عبور (Password Protection) استفاده کن.
۹. آیا صفحات noindex میتوانند در نتایج با URL خالی ظاهر شوند؟
بله، اگر همزمان robots.txt هم آنها را مسدود کرده باشی.در این حالت، گوگل صفحه را نمیبیند اما از طریق لینکها وجودش را حدس میزند و ممکن است URL خام (بدون توضیح) در نتایج بیاید.راهحل:
- یا فقط no index بگذار، بدون Disallow.
- یا هر دو را بردار و Redirect بده.
۱۰. اگر بعداً بخواهم صفحه noindex را دوباره ایندکس کنم، چه باید کرد؟
کافیه تگ no index را حذف کنی یا مقدارش را تغییر بدی به:<meta name=”robots” content=”index, follow”>سپس در Google Search Console → Inspect URL → Request Indexingگوگل صفحه را دوباره بررسی و در ایندکس قرار میدهد.
۱۱. آیا تگ noindex روی subdomain هم اثر دارد؟
بله.هر دامنه یا زیردامنه مستقل باید تنظیمات no index خودش را داشته باشد.اگر در example.com صفحهای نو ایندکس گذاشتی، آن دستور روی blog.example.com تأثیری ندارد مگر اینکه همان تگ در آن هم باشد.
۱۲. آیا وجود تعداد زیاد صفحات no index برای سئو مضر است؟
خیر، تا زمانی که منطقی و هدفمند باشند.درواقع یکی از نشانههای سئوی حرفهای این است که بدانیم چه چیزی باید در ایندکس بماند و چه چیزی حذف شود.اما اگر اشتباهی صفحات ارزشمند را noindex کنی، قطعاً ضرر دارد. بنابراین همیشه از Coverage Report برای کنترل استفاده کن
۱۳. اگر صفحه no index بکلینک بگیرد، ارزشش منتقل میشود؟
بله اگر از no index, follow استفاده شده باشد، لینکاکوئیتی (Link Equity) از آن صفحه به صفحات لینکشده منتقل میشود.اما اگر nofollow باشد، ممکن است انتقال سیگنال متوقف شود.
۱۴. آیا noindex باعث میشود گوگل عنوان یا توضیح صفحه را نادیده بگیرد؟
بله، وقتی صفحهای نو ایندکس میشود، گوگل معمولاً عنوان (Title) و متای آن را در نتایج نمایش نمیدهد.اما همچنان ممکن است از آن دادهها برای درک ساختار سایت استفاده کند.
۱۵. آیا لازم است در نسخه موبایل و دسکتاپ جداگانه نو ایندکس بگذاریم؟
خیر اگر ساختار سایت واکنشگرا (Responsive) باشد، noindex tag در HTML مشترک است و برای هر دو نسخه اعمال میشود.اما اگر نسخه موبایل URL جدا دارد (m.example.com)، باید در هر دو نسخه تگ جداگانه اضافه شود.
۱۶. آیا تگ نو ایندکس صفحات را سریعتر از ایندکس خارج میکند یا باید منتظر باشم؟
گوگل معمولاً پس از Crawl مجدد، دستور نو ایندکس را بلافاصله اعمال میکند.برای سرعت بیشتر میتونی از گزینهی “Removals” در Search Console استفاده کنی تا بهصورت موقت (تا ۶ ماه) URL را از نتایج پاک کند.
۱۷. آیا استفاده زیاد از no index باعث کاهش Crawl Budget میشود؟
در کوتاهمدت بله، چون ربات مدتی وقت صرف بررسی صفحاتی میکند که نباید ایندکس شوند.اما در بلندمدت، Crawl Budget آزاد میشود و به نفع صفحات اصلی تمام میشود.
۱۸. آیا no index در Bing، Yahoo و سایر موتورهای جستجو هم کار میکند؟
بله، تقریباً همهی موتورهای اصلی از no index پشتیبانی میکنند.حتی اگر بخواهی فقط برای گوگل تنظیم کنی، میتونی از: <meta name=”googlebot” content=”no index”>استفاده کنی.
۱۹. آیا no index در صفحات AMP تفاوت دارد؟
خیر، دقیقاً همان عملکرد را دارد.فقط باید در نسخه AMP هم همان متا را داخل <head> اضافه کنی.
۲۰. آیا no index جایگزین حذف فیزیکی صفحه از سایت است؟
خیر.نو ایندکس فقط به گوگل میگوید «نمایشش نده»، اما فایل هنوز روی سرور وجود دارد.اگر هدفت حذف کامل است، باید صفحه را حذف فیزیکی یا Redirect 301 کنی.
سخن آخر درباره تگ نو ایندکس
تگ noindex یکی از حیاتیترین ابزارهای مدیریت ایندکس در سئوی مدرن است.به کمک آن میتوانی ساختار ایندکس را کنترل کنی، صفحات غیرضروری را حذف، و بودجه خزش (Crawl Budget) را صرف صفحات ارزشمند کنی.
در طول مقاله یاد گرفتیم:
- نو ایندکس دقیقاً چیست و چطور کار میکند.
- چه فرقی با robots.txt و canonical دارد.
- چطور آن را در HTML، سرور و CMSها پیاده کنیم.
- چطور عملکردش را در Search Console تحلیل کنیم.
- و در نهایت، چطور هوشمندانه تصمیم بگیریم چه صفحاتی را از ایندکس حذف کنی.
به بیان ساده:
“no index مثل نگهبان باهوش گوگل است؛ نمیگذارد هر کسی وارد سالن اصلی نتایج شود!” اگر نمیدانی کدام صفحات سایتت باید تگ نو ایندکس شوند تا سئوی سایتت سبک، دقیق و حرفهایتر شود،همین حالا آدرس سایتت را برای ما بفرست.متخصصان استارتاپ نمو در کمتر از ۲۴ ساعت یک «گزارش ایندکس هوشمند» رایگان برایت آماده میکنند تا بفهمی کدام صفحات باید بمانند و کدامها باید خداحافظی کنند.
مقالات مرتبط

طراحی سایت وکالت : 0تا100 راهنمای جامع طراحی سایت حقوقی برای وکلا
در دنیای امروز، داشتن یک سایت حرفهای و بهینه برای وکلا و دفاتر وکالت بیش از هر زمان دیگری اهمیت پیدا کرده است. سایتها نه تنها بهعنوان ویترین دیجیتال یک کسبوکار عمل میکنند بلکه نقش حیاتی در جذب مشتریان جدید...

ساخت عکس با هوش مصنوعی | معرفی ۵ ابزار برای خلق تصاویر عالی
“آنچه ذهن میسازد، دنیای واقعیتها را میسازد.” این جمله میتواند دقیقاً به فرآیند تولید تصاویر با استفاده از هوش مصنوعی ربط پیدا کند. هوش مصنوعی بهطور شگفتانگیزی این امکان را فراهم کرده که از تنها چند کلمه، تصاویری خلق کنیم...
زمان مطالعه: 6 دقیقه
پروتکل چیست؟0تا 100راهنمای حرفهای برای انتخاب بهترین پروتکل
«اگر درک نکنیم که چطور باید با یکدیگر ارتباط برقرار کنیم، از رسیدن به مقصد خیلی دور خواهیم بود.» این جمله شاید ساده به نظر بیاید، اما در دنیای دیجیتال و شبکههای پیچیدهای که امروزه داریم، معنای عمیقی دارد. در...
زمان مطالعه: 9 دقیقه